V6N2: Towards a Transmedia Search Engine: A User Study on Perceiving Analogies in Multimedia Data
By Victoria Petite, H. Quynh Dinh, Ebon Fisher | March 5, 2013
Introduction
We are inspired by the ability of artists and designers to find analogies between diverse artifacts and bring them together to compose a coherent and novel narrative. An extreme form of this ability is the neurological condition known as synaesthesia in which two or more senses are crossed (e.g., when seeing a color causes one to hear a sound). In addition to highly-regarded artists who are synaesthetic (e.g., Kandinsky), there are also many examples of attempts to reproduce the effects of synaesthesia in art and entertainment (e.g., the video game Rez (1). Inspired by this phenomenon, we are building a Transmedia Search Engine to enable the exploration of analogies in mixed-media content. To find the most effective algorithms to achieve this goal, we are studying how people perceive analogies between and within media forms (audio samples, images, and videos). In this paper, we describe the development and results of two surveys that we have conducted on analogies between images.
The practice of correlating different media forms has appeared throughout art history and has become even more significant in the last few decades as digital media technology has matured. An early example of analogy between different art forms is the relationship between Miro paintings and Calder sculptures. More recently, different media forms have been fused in mixed-media installations, theatre, concerts, and in visual music (2) where one media form (e.g., an animation) is constructed to synchronize with another (e.g., music).
The emergence of the World Wide Web as a storehouse for archiving and sharing multimedia data has enabled a different mindset – that of gathering (and adapting) existing media content rather than synthesizing new media content to build a coherent mixed-media narrative. To do so, efficient algorithms are needed to search multimedia data. Most search algorithms are text-based and rely on filenames or text tags attached to the file. Those that do not rely on text are content-based approaches that rely on meta-data extracted from the media content. There are two limitations of existing text-based and content-based search engines that our research aims to address: (1) existing search engines focus on literal and exact matches, and (2) they do not compare different media forms. Human cognition is much more complex, however. We typically use visual or phonetic comparisons that are then secondarily translated into language for further communication. Further, we often perceive similarities between different media forms and find analogies in non-literal, inexact matches.
The goal of our Transmedia Search Engine is to enable people to discover non-literal connections between text, audio samples, images, 3D geometry, and videos. It is based on the psychological notion of transderivational search, which is a fuzzy match that enables people to find contextual meaning in every stimulus and forms a primary component of human language and cognitive processing. Once built, the Transmedia Search Engine will form the core of brainstorming and discovery tools for artists to help them make mental associations in design tasks such as gathering media artifacts for a thematic installation from an archive of media samples. As artists navigate this design space, the search engine will present unexpected media possibilities. In another potential application, the search engine can be part of an interactive environment that matches the social pattern (geometry, position, and motion) of participants to media samples that are then displayed in the environment as shown in Figure 1 on the opposite page.

Figure 1 Examples of using search in mixed-media installations. Installations at the Flytrap Gallery and Test-Site Gallery in Brooklyn,
NY (left, center). Mock-up of interactive installation in the green-screen room at Stevens (right).
We now review current trends in search engine technology and pattern matching algorithms that use meta-representations to find similar patterns rather than exact matches. We emphasize that this report does not present a working Transmedia Search Engine, but rather, introduces the concept of such a search engine, describes the limitations of existing search technology, and presents the results of user studies on perceiving analogies that will inform our design of algorithms toward a Transmedia Search Engine. We describe the development of the user studies in Section III and discuss the results in Section IV.
Related Work
The World Wide Web has become a reliable and fast way to archive and share multimedia data. Most search engines (e.g., Google) are text-based and rely on filenames or text tags attached to the file to search multimedia data. Within the last five years, however, many content-based search algorithms have been developed that do not rely on text, and instead compare media content using pattern-matching algorithms.
Content-based Search
Content-based approaches have been developed for retrieval, categorization, and automated annotation of images (3) and video. (4) Non-textual search engines have also been developed for music (5) and 3D shapes. (6) These approaches focus on categorical and literal matching and do not compare different media forms. Related work that does make use of multimedia data are those that integrate multimodal sensor data (e.g., audio and video) to improve tracking and surveillance. (7) Although our goals differ, the meta-data (e.g., local geometric features (8),(9) these methods extract to compare media of a common form may be useful in comparing different media forms and finding nonliteral associations.
Multimedia Clustering
Related to content-based search are methods that integrate both semantics (in the form of text) and content for organizing an image collection. (10) These approaches primarily deal with image databases. They attempt to learn relationships between text and image features such as the color histogram or segmentations of an image and use these relationships to perform text queries on the database and cluster images into categories.
Analogy-Finding
Content-based retrieval algorithms strive to identify or categorize media content given a media sample. In contrast, the goal of our Transmedia Search Engine is to find nonliteral, inexact matches. Few algorithms address this goal, but one that does for images is that of Shechtman and Irani who extract meta-data that preserves structural similarity while being invariant to absolute appearance information such as color and texture. (11) The resulting matches are similar while being non-literal and inexact, which is what we would like to achieve across different media forms.
Methodology
To build a Transmedia Search Engine that suggests analogies in a content-based (rather than textually-based) manner, we need to build algorithms that can extract metadata from media content and compare media samples based on that meta-data as shown in Figure 2.
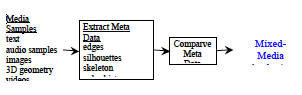
Figure 2 Transmedia search pipeline
For images, meta-data might be in the form of edges or silhouettes extracted from the image that defines the shape of objects therein. A histogram of the color content of an image or video is another example of meta-data. Ideally, the meta-data should record information related to how analogies are perceived. To find out what meta-data should be used in our Transmedia Search Engine, we have developed two user studies on perceiving analogies, focusing on five different visual elements: subject, shape, color, tone (lightness/ darkness), and texture.
Visual Elements
The five visual elements we focus on are the primary components of formal composition upon which critical analysis of artwork is based. These elements have also been identified by researchers in visual perception, neurophysiology, and computer vision as integral to the process of object recognition and identification.
Researchers in visual perception have identified two key steps in the process of visual object recognition. These are object detection and categorization. (12) Detection involves low-level visual processing such as extracting edges and segmenting objects in the foreground from the background. (13) Categorization involves high-level cognitive processing to group a detected object with existing objects in the knowledge base. The computer vision community has developed many algorithms to perform these steps for automated object recognition in images and videos. In our study, these two crucial steps map to the visual elements of subject (for categorization) and shape (for detection).
Interestingly, color and form are processed in different areas of the cortex, and studies have shown that color actually enhances recognition. (14) Color is also known to improve low-level vision tasks such as edge detection and object segmentation. (15) With regard to texture, studies by neurophysiological researchers have shown that neurons in primate visual systems respond to texture in addition to color and shape. (16) Finally, the visual element of tone or lightness/darkness affects perceived shape and subject matter. (17)
Online Surveys
We conducted two types of surveys. The first is designed to capture participants’ visceral reactions on how two media samples relate, while the second delves deeper into why two media samples are perceived as similar. At present, our surveys allow participants to compare only images. In future work, we will conduct surveys on perceiving analogies between media of different forms such as between an image and video segment or an image and a 3D model.
The surveys are web-based and run locally on an APACHE web server. In future work, we will launch these surveys on the web for a larger user study. SQLite is used for data storage. HTML, PHP, CSS, JavaScript, and Flash are used to display and format the surveys.
Survey I
Recent studies have shown that detection involving lowlevel vision and categorization involving cognition are closely coupled and are often performed simultaneously. (18) Although there is still debate about whether detection necessarily occurs before categorization, identification has been found to require more processing time. In the context of a search engine, identification leads to exact matches, whereas detection and categorization lead to inexact, possibly non-literal, matches. To capture the visceral perception of categories, our first survey records perceived similarity without reference to visual elements (Figure 3). The survey displays two random images and asks participants to rate the similarity on a scale of 1 (not similar) to 5 (very similar). Survey participants were asked to spend no more than five minutes comparing each pair of images, and the response time was three minutes on average. Thirty six participants spent approximately one hour each to rate an average of 1000 pairs of images.
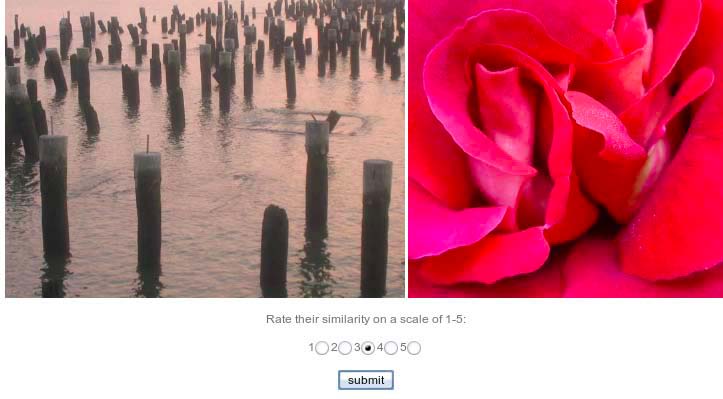
Figure 3 Survey i
Survey II
The goal of the second survey is to determine which of the five visual elements are most influential in perceiving analogies or similarity between images. To do so, participants are shown six images and asked to choose the two most similar pair. They are then asked how the five visual elements (subject, shape, color, texture, and tone) affected their selection by rating how similar each element is in the selected pair of images on a scale of 1 (not similar) to 5 (very similar). Survey participants were asked to spend no more than 5 minutes selecting and rating each pair of images. Participants can ask for a new set of six images as many times as needed if they did not perceive any pair to be similar. In our study, new image sets were requested 66% of the time. 40 participants rated an average of 1000 pairs of images.
Results and Discussion
We now discuss the results of our surveys and the conclusions we can infer from the data.
Survey I
Images were found to be similar 72% of the time. The following plot shows how participants rated the similarity of a pair of random images on a scale of 1 (not similar) to 5 (very similar).
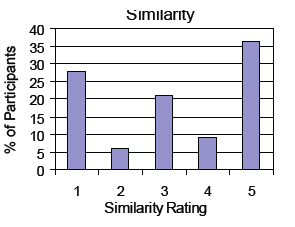
Approximately 1/3 of the responses indicated that the images are very similar (rating of 5), 1/3 indicated little or no similarity (rating of 1 and 2), and approximately 1/3 found some similarity (rating of 3 and 4), reflecting the diversity in the data. Results reveal that given two image samples, people tend to find some similarity (rating or 1 or higher) and that there may be a psychological bias towards looking for and finding similarity. Although Survey I is not particularly informative about how non-literal similarities are perceived, it does positively indicate that inexact, or analogical, matches are perceived and should be pursued. As we describe next, our second survey leads to more interesting conclusions on perceiving similarity.
Survey II
The results of our second survey are shown in the following plot. The similarity rating on a scale of 1 (not similar) to 5 (very similar) for each element is plotted against the percentage of participants who chose each rating. The ratings essentially reveal the influence of the visual element on perceiving similarity since participants rate the visual elements only once they have deemed a pair of images to be similar.
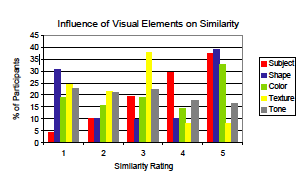
Based on the findings in the plot above, we make the following conclusions:
By examining the highest rating of 5, we see that subject, shape, and color are most often identified as the reason for perceiving similarity.
Based on the trend for each visual element, we see that subject (with the smallest percentage of “no similarity” or 1 rating), correlates most consistently with the perception of similarity.
The shapes in the images are either very similar or not similar at all, indicating that people may find image pairs to be similar despite having completely different shapes (most likely, subject and/or color were perceived to be similar in these cases). This result also indicates that shape is strongly perceived to be similar or different, and not often perceived to be just mildly similar.
Texture and tone do not appear to be highly correlated with similarity, and their ratings follow normal and nearly constant curves, respectively.
Although Survey II does not directly measure it, we make the intuitive conclusion that for more abstract image pairs, shape and color are likely to be influential, whereas for representational image pairs, subject dominates.
To further analyze the survey data, we have correlated the different visual elements. In the following table we record the percentage of time when two visual elements are identified as being very similar (rating of 5) in a pair of images. Each cell is the percentage of time that the associated row’s visual element was rated as very similar given that the column’s visual element was rated as very similar. For example, when subject was rated as very similar (first column), texture was also rated as very similar only 2% of the time.
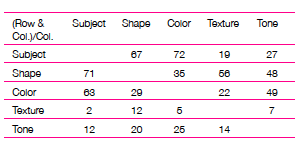
Table 1-Correlation (%) of visual elements
The correlation percentages reveal which visual elements can be used as indicators of others. Subject is a strong indicator that shape is also similar by 71% and visa versa by 67%. This information is vital in that it enables us to infer the similarity of one visual element based on another. For example, we can infer subject similarity based on shape similarity (with 67% confidence) and rely on computer vision algorithms to robustly measure shape similarity in our Transmedia Search Engine.
Future Work
We have described user studies we have conducted on perceiving similarity in images. Our results show that subject and shape are leading factors in determining similarity and are highly correlated. The results will inform our design of algorithms toward an analogical search engine that we call the Transmedia Search Engine. Our next step is to conduct surveys using different media forms (e.g., images and video segments, and images and 3D shapes) and to launch the surveys on the web for wider audience participation.
Acknowledgements
This work was funded in part by NSF CreativeIT Award# IIS-0742440 and the Stevens Technogenesis Summer Scholars Program for undergraduate inter-disciplinary research.
Footnotes:
- Andrew Vestal, “Rez,” The Gaming Intelligence Agency (2002), http://microscopiq.com/extras/Rez.html (accessed March 3, 2009).
- Oskar Fischinger (director). Oskar Fischinger: Ten Films, 2006, Wayne Lytle (director), Animusic: A Computer Animation Video Album, 2001, and J. B. Mitroo, Nancy Herman, and Norman I. Badler, “Movies From Music: Visualizing Musical Compositions”, Proceedings of 6th International Conference on Computer Graphics and Interactive Techniques (SIGGRAPH), (1979):218-225.
- Riya Visual Search. http://www.riya.com (accessed March 3, 2009); Kobus Barnard and David A. Forsyth, “Learning the Semantics of Words and Pictures,” Proceedings of International Conference on Computer Vision (ICCV), 2 (2001):408- 415; Ritendra Datta, Dhiraj Joshi, Jia Li, and James Z. Wang, “Image Retrieval: Ideas, Influences, and Trends of the New Age,’’ ACM Computing Surveys (CSUR), 40 No 2 (2008):Article 5; Yong Rui, Thomas S. Huang, and Shih-Fu Chang, “Image retrieval: Current Techniques, Promising Directions and Open Issues”, Journal of Visual Communication and Image Representation, 10 No 1 (March 1999):39-62; Arnold Smeulders, Marcel Worring, Simone Santini, Amarnath Gupta, and Ramesh Jain, “Content-based Image Retrieval at the End of the Early Years”, IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), 22 No 12 (2000):1349-1380; and Remco Veltkamp and Mirela Tanase, “Content-based Image Retrieval Systems: A Survey”, Technical Report UUCS- 2000-34, Department of Computing Science, Utrecht University, 2000.
- Philippe Aigrain, Hongjiang Zhang, and Dragutin Petkovic, “Content-based Representation and Retrieval of Visual Media: a State of the Art Review”, Multimedia Tools and Applications, 3 No 3 (1996):179 – 202; Shih-Fu Chang, Qian Huang, Thomas Huang, Atul Puri, and Behzad Shahraray, “Multimedia search and retrieval”, Advances in Multimedia: Systems, Standards, and Networks, edited by Atul Puri and Tsuhan Chen, New York: Marcel Dekker, 1999; and James Z. Wang and Nozha Boujemaa (eds). Proceedings of ACM SIGMM 8th International Workshop on Multimedia Information Retrieval (MIR), 2006.
- Midomi. http://www.midomi.com/ (accessed March 3, 2009).
- Princeton Shape Benchmark. http://shape.cs.princeton.edu/ benchmark (accessed March 3, 2009), and Robert Osada, Thomas Funkhouser, Bernard Chazelle and David Dobkin, “Shape Distributions”, ACM Transactions on Graphics, 21 No 4 (2002):807-832.
- Zohar Barzelay and Yoav Y. Schechner, “Harmony in Motion”, Proceedings of Conf. Computer Vision and Pattern Recognition (CVPR), 1 (2007):1-8; Adam O’Donovan, Ramani Duraiswami, and Jan Neumann, “Microphone Arrays as Generalized Cameras for Integrated Audio Visual Processing”, Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), (June 2007):1-8; and Zhigang Zhu, Tom S. Huang, and Ying-li Tian (eds). Proceedings of IEEE Workshop on Multimodal Sentient Computing: Sensors, Algorithms and Systems (WMSC07), part of the Conference Computer Vision and Pattern Recognition (CVPR), 2007.
- Krystian Mikolajczyk and Cordelia Schmid, “A Performance Evaluation of Local Descriptors”, IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 27 No 10 (October 2005):1615-1630.
- Simon A.J. Winder and Matthew Brown, “Learning Local Image Descriptors”, Proceedings of Conference Computer Vision and Pattern Recognition (CVPR), (2007):1-8.
- Kobus Barnard and David A. Forsyth, “Learning the Semantics of Words and Pictures”, Proceedings of International Conference on Computer Vision (ICCV), 2 (2001):408-415; Kobus Barnard, Pinar Duygulu, and David A. Forsyth, “Clustering Art”, Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), 2 (2001): 434–441; Ron Bekkerman and Jiwoon Jeon, “Multi-modal Clustering for Multimedia Collections”, Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), 1 (2007):1-8; Deng Cai, Xiaofei He , Zhiwei Li , Wei-Ying Ma, and Ji-Rong Wen, “Hierarchical Clustering of WWW Image Search Results Using Visual, Textual and Link Information”, Proceedings of the 12th International Conference on Multimedia, (2004):1919- 1932; Nicolas Loeff, Cecilia O. Alm, and David A. Forsyth, “Discriminating Image Senses by Clustering with Multimodal Features”, Proceedings of COLING/ACL, (2006):547-554; and Yukio Uematsu, Ryoji Kataoka, and Hiroshi Takeno, “Clustering Presentation of Web Image Retrieval Results Using Textual Information and Image Features”, Proceedings of the 24th IASTED International Conference on Internet and Multimedia Systems and Applications, (2006):217-222.
- Eli Shechtman and Michal Irani, “Matching Local Selfsimilarities Across Images and Videos”, Proceedings of Conf. Computer Vision and Pattern Recognition (CVPR), (2007):1-8.
- J. Driver and G.C. Baylis, “Edge-assignment and Figureground Segmentation in Short-term Visual Matching”, Cognitive Psychology, 31 (1996):248-306; Ken Nakayama, Zijiang J. He, and Shinsuke Shimojo, “Visual Surface Representation: A Critical Link Between Lower-level and Higher-level Vision”, In An Invitation to Cognitive Science: Visual Cognition, edited by Stephen M. Kosslyn and Daniel N. Osherson, 1-70. Cambridge, MA: MIT Press, 1995; and Thomas J. Palmeri and Isabel Gauthier, “Visual Object Understanding”, Nature Reviews, Neuroscience, 5 (April 2004):291–303.
- Min C. Shin, Dmitry B. Goldgof, and Kevin W. Bowyer, “Comparison of Edge Detector Performance Through Use in an Object Recognition Task”, Computer Vision and Image Understanding (CVIU), 84 No 1 (2001):160-178.
- K.R. Gegenfurtner, and J. Rieger, “Sensory and Cognitive Contributions of Color to the Recognition of Natural Scenes”, Current Biology, 10 (2000):805-808; Ian Spence, Patrick Wong, Maria Rusan, and Naghmeh Rastegar, “How Color Enhances Visual Memory for Natural Scenes”, Psychological Science, 17 No 1 (2006):1-6.
- Ione Fine, Donald I.A. Macleod, and Geoffrey M. Boynton, “Surface Segmentation Based on the Luminance and Color Statistics of Natural Scenes”, Journal of the Optical Society of America, 20 (2003):1283-1291.
- E. Kobatake and K. Tanaka, “Neuronal Selectivities to Complex Object Features in the Ventral Visual Pathway of the Macaque Cerebral Cortex”, Journal of Neurophysiology, 71 (1994):856-867; Nikos K. Logothetis, J. Pauls, Heinrich Bulthoff, and Thomas Poggio, “View-dependent object recognition by monkeys”, Current Biology, 4 (1994):401-414; and Bartlett W. Mel, “SEEMORE: Combining Color, Shape, and Texture Histogramming in a Neurally Inspired Approach to Visual Object Recognition”, Neural Computation, 9 (1997):777- 804.
- Barton L. Anderson and Jonathan Winawer. “Image segmentation and lightness perception”, Nature (Letters to Nature), 434 No 7029 (2005):79-83.
- Kalanit Grill-Spector and Nancy Kanwisher, “Visual Recognition: As Soon As You Know It Is There, You Know What It Is”, Psychological Science, 16 No 2 (2005):152-160; Eric Halgren, Janine Mendola, Catherine D.R. Chong, and Anders M. Dale, “Cortical Activation to Illusory Shapes as Measured with Magnetoencephalography”, NeuroImage, 18 (2003):1001-1009; Shaul Hochstein and Merav Ahissar, “View From the Top: Hierarchies and Reverse Hierarchies in the Visual System”, Neuron, 36 (2002):791-804; Jia Liu, Alison Harris and Nancy Kanwisher, “Stages of Processing in Face Perception: An MEG Study”, Nature Neuroscience, 5 No 9 (September 2002):910-916; and Michael L. Mack, Isabel Gauthier, Javid Sadr, and Thomas J. Palmeri, “Object Detection and Basiclevel Categorization: Sometimes You Know It Is There Before You Know What It Is”, Psychonomic Bulletin & Review, 15 No 1 (2008):28-35.
Works Cited:
Aigrain, Philippe, Hongjiang Zhang, and Dragutin Petkovic. “Content-based Representation and Retrieval of Visual Media: a State of the Art Review,” Multimedia Tools and Applications, 3 No 3 (1996):179-202.
Anderson, Barton L. and Jonathan Winawer. “Image Segmentation and Lightness Perception,” Nature (Letters to Nature), 434 No 7029 (2005):79-83.
Barnard, Kobus and David A. Forsyth. “Learning the Semantics of Words and Pictures,” Proceedings of International Conference on Computer Vision (ICCV), 2 (2001):408-415.
Barnard, Kobus, Pinar Duygulu, and David A. Forsyth. “Clustering Art,” Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), 2 (2001): 434–441.
Barzelay, Zohar and Yoav Y. Schechner. “Harmony in Motion,” Proceedings of Conf. Computer Vision and Pattern Recognition (CVPR), 1 (2007):1-8.
Bekkerman, Ron and Jiwoon Jeon. “Multi-modal Clustering for Multimedia Collections,” Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), 1 (2007):1-8.
Cai, Deng, Xiaofei He , Zhiwei Li , Wei-Ying Ma, and Ji-Rong Wen. “Hierarchical Clustering of WWW Image Search Results Using Visual, Textual and Link Information,” Proceedings of the 12th International Conference on Multimedia, (2004):1919-1932.
Chang, Shih-Fu, Qian Huang, Thomas Huang, Atul Puri, and Behzad Shahraray. “Multimedia search and retrieval,” chapter in Advances in Multimedia: Systems, Standards, and Networks, edited by Atul Puri and Tsuhan Chen, New York: Marcel Dekker, 1999.
Datta, Ritendra, Dhiraj Joshi, Jia Li, and James Z. Wang. “Image Retrieval: Ideas, Influences, and Trends of the New Age,’’ ACM Computing Surveys (CSUR), 40 No 2 (2008): Article 5.
Driver, J. and G.C. Baylis. “Edge-assignment and Figureground Segmentation in Short-term Visual Matching,” Cognitive Psychology, 31 (1996):248-306.
Fine, Ione, Donald I.A. Macleod, and Geoffrey M. Boynton. “Surface Segmentation Based on the Luminance and Color Statistics of Natural Scenes,” Journal of the Optical Society of America, 20 (2003):1283-1291.
Fischinger, Oskar (director). Oskar Fischinger: Ten Films, 2006. Gegenfurtner, K.R. and J. Rieger. “Sensory and Cognitive Contributions of Color to the Recognition of Natural Scenes,” Current Biology, 10 (2000):805-808.
Grill-Spector, Kalanit and Nancy Kanwisher. “Visual Recognition: As Soon As You Know It Is There, You Know What It Is,” Psychological Science, 16 No 2 (2005):152-160.
Halgren, Eric, Janine Mendola, Catherine D.R. Chong, and Anders M. Dale. “Cortical Activation to Illusory Shapes as Measured with Magnetoencephalography,” NeuroImage, 18 (2003):1001-1009.
Hochstein, Shaul and Merav Ahissar. “View From the Top: Hierarchies and Reverse Hierarchies in the Visual System,” Neuron, 36 (2002):791-804.
Kobatake, E. and K. Tanaka. “Neuronal Selectivities to Complex Object Features in the Ventral Visual Pathway of the Macaque Cerebral Cortex,” Journal of Neurophysiology, 71 (1994):856-867.
Liu, Jia, Alison Harris and Nancy Kanwisher. “Stages of Processing in Face Perception: An MEG Study,” Nature Neuroscience, 5 No 9 (September 2002):910-916.
Loeff, Nicolas, Cecilia O. Alm, and David A. Forsyth. “Discriminating Image Senses by Clustering with Multimodal Features,” Proceedings of COLING/ACL, (2006):547-554.
Logothetis, Nikos K., J. Pauls, Heinrich Bulthoff, and Thomas Poggio. “View-dependent object recognition by monkeys,” Current Biology, 4 (1994):401-414.
Lytle, Wayne (director). Animusic: A Computer Animation Video Album, 2001.
Mack, Michael L., Isabel Gauthier, Javid Sadr, and Thomas J. Palmeri. “Object Detection and Basic-level Categorization: Sometimes You Know It Is There Before You Know What It Is,” Psychonomic Bulletin & Review, 15 No 1 (2008):28-35.
Mel, Bartlett W. “SEEMORE: Combining Color, Shape, and Texture Histogramming in a Neurally Inspired Approach to Visual Object Recognition,” Neural Computation, 9 (1997):777-804.
Midomi. http://www.midomi.com/
Mikolajczyk, Krystian and Cordelia Schmid. “A Performance Evaluation of Local Descriptors,” IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 27 No 10 (October 2005):1615-1630.
Mitroo, J. B., Nancy Herman, and Norman I. Badler. “Movies From Music: Visualizing Musical Compositions,” Proceedings of 6th International Conference on Computer Graphics and Interactive Techniques (SIGGRAPH), (1979):218-225.
O’Donovan, Adam, Ramani Duraiswami, and Jan Neumann. “Microphone Arrays as Generalized Cameras for Integrated Audio Visual Processing,” Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), (June 2007):1-8.
Nakayama, Ken, Zijiang J. He, and Shinsuke Shimojo. “Visual Surface Representation: A Critical Link Between Lower-level and Higher-level Vision,” In An Invitation to Cognitive Science: Visual Cognition, edited by Stephen M. Kosslyn and Daniel N. Osherson, 1-70. Cambridge, MA: MIT Press, 1995.
Osada, Robert, Thomas Funkhouser, Bernard Chazelle and David Dobkin. “Shape Distributions,” ACM Transactions on Graphics, 21 No 4 (2002):807-832.
Palmeri, Thomas J. and Isabel Gauthier. “Visual Object Understanding,” Nature Reviews, Neuroscience, 5 (April 2004):291– 303.
Princeton Shape Benchmark. http://shape.cs.princeton.edu/ benchmark/
Riya Visual Search. http://www.riya.com/ (accessed March 3, 2009).
Rui, Yong, Thomas S. Huang, and Shih-Fu Chang, “Image retrieval: Current Techniques, Promising Directions and Open Issues,” Journal of Visual Communication and Image Representation, 10 No 1 (March 1999):39-62.
Shechtman, Eli and Michal Irani. “Matching Local Self-similarities Across Images and Videos,” Proceedings of Conf. Computer Vision and Pattern Recognition (CVPR), (2007):1-8.
Shin, Min C., Dmitry B. Goldgof, and Kevin W. Bowyer. “Comparison of Edge Detector Performance Through Use in an Object Recognition Task,” Computer Vision and Image Understanding (CVIU), 84 No 1 (2001):160-178.
Smeulders, Arnold, Marcel Worring, Simone Santini, Amarnath Gupta, and Ramesh Jain, “Content-based Image Retrieval at the End of the Early Years,” IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), 22 No 12 (2000):1349-1380.
Spence, Ian, Patrick Wong, Maria Rusan, and Naghmeh Rastegar. “How Color Enhances Visual Memory for Natural Scenes,” Psychological Science, 17 No 1 (2006):1-6.
Uematsu, Yukio, Ryoji Kataoka, and Hiroshi Takeno. “Clustering Presentation of Web Image Retrieval Results Using Textual Information and Image Features,” Proceedings of the 24th IASTED International Conference on Internet and Multimedia Systems and Applications, (2006):217-222.
Veltkamp, Remco and Mirela Tanase. “Content-based Image Retrieval Systems: A Survey,” Technical Report UU-CS-2000-34, Department of Computing Science, Utrecht University, 2000.
Vestal, Andrew. “Rez,” The Gaming Intelligence Agency (2002), http://microscopiq.com/extras/Rez.html (accessed March 3, 2009).
Wang, James Z. and Nozha Boujemaa (eds). Proceedings of ACM SIGMM 8th International Workshop on Multimedia Information Retrieval (MIR), 2006.
Winder, Simon A.J. and Matthew Brown. “Learning Local Image Descriptors,” Proceedings of Conference Computer Vision and Pattern Recognition (CVPR), (2007):1-8.
Zhu, Zhigang, Tom S. Huang, and Ying-li Tian (eds). Proceedings of IEEE Workshop on Multimodal Sentient Computing: Sensors, Algorithms and Systems (WMSC07), part of the Conference Computer Vision and Pattern Recognition (CVPR), 2007.